

이번 글에서는 RAFT(Retrieval Augmented Fine-Tuning)에 대해 이야기해보려고 합니다. RAFT는 기존의 DSF(Domain-Specific Fine-tuning)와 RAG(Retrieval-Augmented Generation)의 장점을 결합한 혁신적인 방법론인데요, 왜 이런 기술이 필요하게 되었는지, 어떤 특징이 있는지 자세히 살펴보겠습니다.
먼저, 현재 기업들이 LLM을 특정 도메인에 적응시키는 데 주로 사용되는 방법인 DSF와 RAG 방식에 대해 간단히 알아보겠습니다.
[Domain-Specific Fine-tuning (DSF)]DSF는 사전 학습된 대규모 언어 모델(LLM)을 특정 도메인의 데이터로 추가 학습시키는 방법입니다. 이를 통해 모델이 특정 분야의 지식과 언어를 학습하도록 하여 해당 도메인에서의 성능을 향상시킬 수 있습니다.
하지만, DSF에는 몇 가지 한계가 있습니다.
- 과적합의 위험: 특정 도메인에 너무 치우쳐 일반성을 잃을 수 있습니다.
- 지속적인 업데이트 필요 : 새로운 정보가 생길 때마다 모델을 재학습해야 합니다.
- 대규모 데이터셋 요구 : 효과적인 fine-tuning을 위해서는 많은 양의 도메인 특화 데이터가 필요합니다.
RAG는 외부 지식 베이스에서 관련 정보를 검색하여 LLM의 응답 생성을 보강하는 기술입니다. 이 방법을 통해 모델이 최신 정보나 특정 도메인의 지식을 활용할 수 있게 됩니다.
이러한 RAG 역시 DSF와 마찬가지로 몇 가지 한계점이 있습니다.
- 검색 품질 의존성 : 검색된 정보의 품질에 크게 의존하여 부정확한 정보를 제공할 위험이 있습니다.
- 컨텍스트 처리 한계 : 검색된 정보를 효과적으로 통합하는 데 어려움을 겪을 수 있습니다.
- 실시간 처리 지연 : 검색 과정으로 인해 응답 생성 시간이 늘어날 수 있습니다.
이러한 DSF와 RAG의 한계를 극복하고자 UC 버클리의 연구원인 Tianjun Zhang과 Shishir G. Patil이 RAFT라는 새로운 기법을 개발하였습니다. 이들은 이전에 Gorilla LLM 프로젝트로 알려진 연구를 통해 RAFT를 소개하였으며, 이 연구에서는 Meta의 Llama 2 모델과 Azure AI Studio(현. Azure AI Foundry)를 활용하여 RAFT를 구현하였습니다.
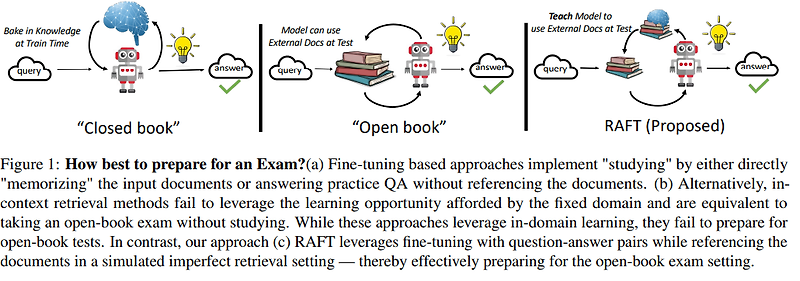
RAFT 논문 (https://arxiv.org/abs/2403.10131)
RAFT의 주요 목표는 다음과 같습니다.
- 도메인 지식 통합 : DSF의 장점을 활용하여 모델에 도메인 특화 지식을 학습시킵니다.
- 검색 robustness 향상 : 부정확한 검색 결과에 대한 모델의 견고성을 높입니다.
- 효율적인 정보 활용 : 검색된 정보를 더 효과적으로 활용하여 응답의 품질을 향상시킵니다.
RAFT는 DSF와 RAG의 장점을 결합한 새로운 방법이에요. 주요 특징을 살펴보겠습니다.
- 통합적 접근: DSF의 도메인 지식 학습과 RAG의 외부 정보 활용을 동시에 활용할 수 있습니다.
- Chain-of-Thought 활용: 모델이 단계별로 추론하는 능력을 키울 수 있습니다.
- Distractor 문서 활용: 관련 없는 문서도 학습에 포함시켜 모델의 견고성을 높여줍니다.
- 효율적인 파인튜닝: 적은 컴퓨팅 파워로도 높은 성능을 달성할 수 있습니다.
그럼 RAFT가 어떻게 동작하는지, 그리고 실제 예제를 통해 그 효과를 살펴보겠습니다.
[RAFT의 동작 원리]RAFT는 RAG(Retrieval-Augmented Generation)와 Fine-tuning의 장점을 결합한 새로운 방식으로 어떻게 동작하는지 단계별로 살펴보겠습니다.
- 데이터 준비:
- 질문(Q)
- 문서 세트(Dk): “오라클” 문서(정답 포함)와 “디스트랙터” 문서(관련 없는 정보)로 구성
- Chain-of-Thought 스타일의 답변(A*)
2. 학습 데이터 구성:
- 일부 데이터: 오라클 문서 + 디스트랙터 문서
- 나머지 데이터: 디스트랙터 문서만
3. 모델 학습:
- 준비된 데이터로 LLM을 파인튜닝
- 모델이 관련 정보를 식별하고 활용하는 방법 학습
4. 평가 및 적용:
- 학습된 모델을 다양한 도메인 특화 태스크에서 평가
- RAG 시스템에 적용하여 성능 향상
우선 RAFT를 이용해 어떤 시나리오가 가능한지 살펴보고 실제 예제를 통해 어떻게 Azure OpenAI로 구현하는지 알아보도록 하겠습니다.
먼저, 금융 거래 시스템을 예로 들어서 전 세계 은행의 거래를 처리하는 분산 시스템을 상상해보겠습니다.
시나리오:
- 고객이 계좌 간 송금을 요청했습니다.
RAFT 적용 전:
- 기존 LLM : “송금 처리를 위해 은행 시스템에 요청을 보냅니다.”
- RAG : “고객의 계좌에서 목표 계좌로 자금을 이체합니다. 이체 금액은 고객 계좌에서 차감되고 목표 계좌에 추가됩니다.”
RAFT 적용 후:
“고객님의 송금 요청을 처리하겠습니다. 먼저, 출금 계좌의 잔액을 확인합니다. 충분한 잔액이 있다면, 해당 금액을 출금 계좌에서 차감하고 수취인의 계좌로 이체합니다. 이 과정에서 은행의 내부 거래 ID가 생성되어 추적됩니다. 송금이 완료되면, 양쪽 계좌의 잔액이 업데이트되고, 거래 내역이 기록됩니다. 이 모든 과정은 분산 시스템 내에서 Raft 합의 알고리즘을 통해 안전하게 복제되어, 모든 노드가 일관된 상태를 유지합니다.”
이 예시에서 볼 수 있듯이, RAFT를 적용한 모델은 금융 도메인의 특수한 지식(계좌 잔액 확인, 거래 ID 생성 등)과 기술적 세부사항(Raft 합의 알고리즘 사용)을 결합하여 더 정확하고 상세한 답변을 제공합니다.
그럼 실제로 어떻게 구현하는지 MS에서 제공하는 샘플을 이용해 살펴보도록 하겠습니다.
샘플 소스 Repo: https://github.com/Azure-Samples/azure-openai-raft
이 GitHub Repository는 Azure OpenAI를 사용하여 Retrieval Augmented Fine Tuning (RAFT)을 구현하는 방법에 대한 단계별 가이드를 제공합니다. RAFT 구현 절차는 다음과 같습니다.
1. 환경 설정- Azure OpenAI 서비스에서 필요한 모델 배포:
- GPT-4o
- ada-002 임베딩
- GPT-4o-mini
- 약 100K TPM의 용량 확보
2. 자격 증명 설정
- sample.env 파일의 내용을 새로운
.env파일로 복사 - 필요한 자격 증명 정보 입력 (FINETUNED 모델 자격 증명은 노트북 2 실행 후 입력 가능)
3. 종속성 설치
- 시스템 종속성 설치:
- Linux:
sudo apt-get install -y poppler-utils - Mac:
brew install poppler - Windows:
conda install -c conda-forge poppler - Python 종속성 설치:
conda create -n raft python=3.11 conda activate raft pip install -r requirements.txt
4. 노트북 실행
- Repository에 포함된 3개의 노트북을 순서대로 실행
1. RAFT 학습 데이터 생성 (노트북 1)
RAFT를 위한 학습 데이터 생성은 모델의 성능에 직접적인 영향을 미치는 중요한 단계입니다. GPT-4o를 활용한 데이터 생성 과정은 다음과 같습니다:
도메인 특화 문서 수집: 의료, 법률, API 문서 등 특정 도메인의 관련 문서를 수집합니다.
문서 청킹: 수집된 문서를 적절한 크기의 청크로 나눕니다.
질문 생성: 각 문서 청크에 대해 답변 가능한 질문들을 생성합니다.
문서 세트 구성:
골든 문서(D*): 질문의 답을 포함하는 문서
디스트랙터 문서(Dk): 관련 없는 정보를 포함하는 문서
질문-답변-문서 트리플 생성: 골든 문서를 기반으로 사실적인 답변을 생성합니다.
이 과정은 GPT-4o를 활용해 초기 학습 예제를 생성하고, 이후 전문가의 검토와 수정을 거치게 됩니다.
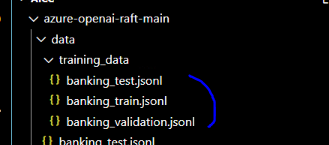
첫 번째 노트북은 GPT-4o를 사용하여 RAFT(Retrieval Augmented Fine Tuning) 훈련 데이터를 생성하는 과정을 설명합니다. BMO 은행 가이드 PDF 문서를 이미지로 변환하고 GPT-4o로 마크다운으로 변환한 후, 문서를 의미론적으로 청크(chunk)로 분할합니다. 각 청크에 대해 5개의 질문을 생성하고, 각 질문-문서 쌍에 대해 답변을 생성합니다. 원본 문서와 방해 문서(distractor documents)를 포함하여 총 훈련 데이터를 만들고, 이를 훈련(80%), 검증(10%), 테스트(10%) 세트로 분할합니다. 최종적으로 JSONL 형식으로 데이터셋을 저장하여 GPT-4o 미니 모델을 특정 도메인에 맞게 미세 조정할 수 있도록 합니다.
해당 노트북 전체를 실행하고 나면 아래와 같은 훈련 데이터가 생성됩니다.
2. RAFT GPT-4o-mini 파인튜닝 (노트북 2)
생성된 학습 데이터를 바탕으로 모델을 파인튜닝하는 과정입니다. Azure OpenAI는 LoRA(Low-Rank Adaptation) 기술을 사용해 효율적인 파인튜닝을 수행합니다.
LoRA의 특징:
모든 모델 파라미터를 조정하지 않고, 소수의 추가 파라미터만 도입
원본 모델 파라미터는 대부분 변경되지 않음
적은 컴퓨팅 리소스로 새로운 태스크 학습 가능
Azure OpenAI는 이 복잡한 과정을 추상화하여 개발자가 쉽게 접근할 수 있도록 합니다.
두 번째 노트북에서는 생성된 데이터로 모델을 실제 미세 조정합니다.주요 단계는 다음과 같습니다.
- PDF 문서를 이미지로 변환하고 마크다운으로 추출
- 문서를 의미론적 청크로 분할
- 각 청크에 대해 5개의 질문 생성
- 질문-문서 쌍에 대한 답변 생성
- 원본 문서와 방해 문서(distractor documents) 포함
- Azure OpenAI를 통해 데이터셋 분할 및 미세 조정 수행
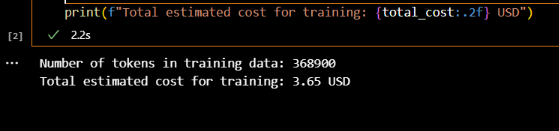
특히 LoRA(Low-Rank Adaptation) 기법을 사용해 모델을 효율적으로 미세 조정하며, 훈련 비용은 약 0.003300 USD per 1K 토큰으로 예측 가능합니다. 최종적으로 은행 도메인에 특화된 GPT-4o-mini 모델을 개발하는 것이 목표입니다.
해당 노트북의 첫번째에는 파인 튜닝 작업 전에 어느 정도의 토큰 비용이 발생하는지에 대해 예상하는 코드가 구현되어 있습니다.
from dotenv import load_dotenv
import os
import tiktoken
import json
from openai import AzureOpenAI
# loading environment variables
dotenv_path = './sample.env'
load_dotenv(dotenv_path)
aoai_endpoint = os.getenv("AOAI_FINETUNING_ENDPOINT")
aoai_api_key = os.getenv("AOAI_FINETUNING_API_KEY")
training_file_path = './data/training_data/banking_train.jsonl'
encoding = tiktoken.encoding_for_model("gpt-4o-mini")
def num_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1):
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "role":
num_tokens += tokens_per_name
num_tokens += 3
return num_tokens
with open(training_file_path, 'r', encoding='utf-8') as f:
num_tokens=0
dataset = [json.loads(line) for line in f]
messages = [ d.get('messages') for d in dataset]
for message in messages:
num_tokens += num_tokens_from_messages(message)
print(f"Number of tokens in training data: {num_tokens}")
training_cost_per_token = 0.003300 / 1000
num_epochs = 3
total_cost = num_tokens * training_cost_per_token * num_epochs
print(f"Total estimated cost for training: {total_cost:.2f} USD")
실제로 실행시켜 보면 아래와 같은 비용이 예상된다고 출력됩니다.
그리고, 해당 노트북을 이어서 실행하면 아래와 같이 파인 튜닝 작업을 실행하게 되고,
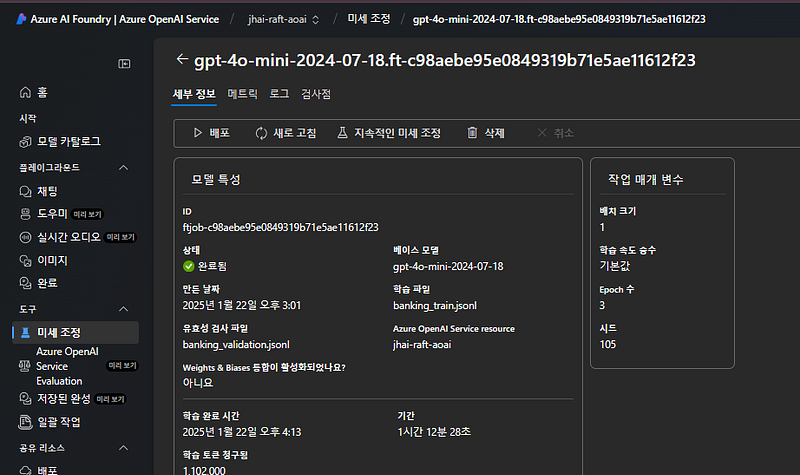
아래와 같이 파인 튜닝 작업의 결과를 메트릭으로 확인해 볼 수 있습니다.
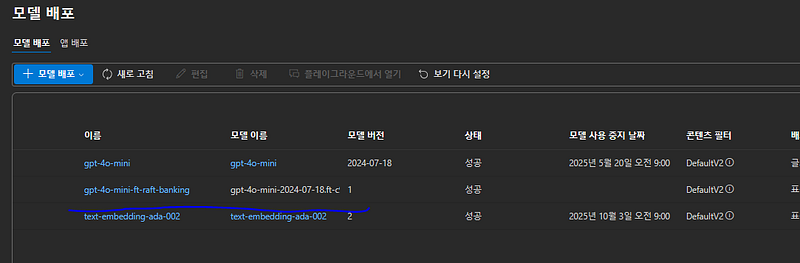
그리고 노트북 실행 최종으로는 아래와 같은 파인튜닝 모델을 배포하게 됩니다.
3. 모델 평가 (노트북 3)
파인튜닝된 모델의 성능을 평가하는 단계입니다. 기본 gpt-4o-mini 모델과 파인튜닝된 모델을 비교합니다.
평가 과정:
테스트 세트 로드
두 모델로 테스트 세트에 대한 추론 수행
Chain of Thought 제거 및 최종 답변만 추출
평가 메트릭 정의
두 모델에 대한 평가 실행
결과 시각화
이 과정을 통해 RAFT가 실제로 모델의 RAG 태스크 성능을 얼마나 향상시켰는지 객관적으로 평가할 수 있습니다.
마지막으로 세 번째 노트북은 GPT-4o 미니 모델을 RAFT(Retrieval Augmented Fine Tuning) 방식으로 미세 조정한 후, 그 성능을 평가하는 과정을 설명합니다. 주요 단계는 다음과 같습니다.
- 테스트 데이터셋 로드
- 기본 모델과 미세 조정된 모델로 테스트 셋에 대한 추론 수행
- 모델 답변에서 최종 답변만 추출하여 정제
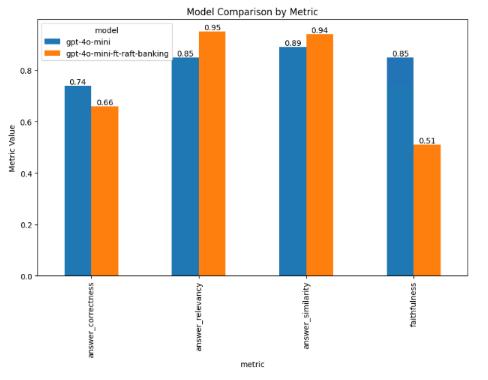
- RAGAS 프레임워크를 사용한 평가 지표 정의 (답변 관련성, 충실도, 유사성, 정확성)
- 두 모델에 대해 평가 지표 계산
- 결과를 시각화하여 모델 간 성능 비교
평가 결과, 미세 조정된 모델이 기본 모델보다 대부분의 지표에서 더 나은 성능을 보였습니다. 이는 RAFT 방식이 모델의 RAG 작업 성능을 향상시키는 데 효과적임을 보여줍니다.
이 과정을 통해 RAFT를 구현하고, 도메인 특화 RAG(Retrieval-Augmented Generation)를 위한 언어 모델 적응을 수행할 수 있습니다. RAFT는 특정 도메인의 문서 세트에 대해 더 나은 RAG 성능을 달성하도록 모델을 훈련시키는 방법을 제시합니다.
[RAFT의 성능은 어떨까?]RAFT는 다양한 도메인에서 놀라운 성능을 보여주고 있습니다. 특히 의학 분야(PubMed), 복잡한 추론(HotpotQA), API 호출(Gorilla) 등의 태스크에서 기존 방법들을 압도하였으며, 가장 놀라운 점은 RAFT가 LLaMA-2 7B라는 비교적 작은 모델로 GPT-3.5에 버금가는 성능을 냈는데요. 이는 RAFT가 얼마나 효율적인지를 잘 보여주는 결과로 볼 수 있습니다.
[RAFT의 미래는?]RAFT는 앞으로 더욱 발전할 것으로 보이며, 예상되는 발전 방향은 다음과 같습니다.
- 멀티모달 확장 : 텍스트뿐만 아니라 이미지, 음성 등 다양한 형태의 데이터를 처리.
- 실시간 학습 : 계속 변화하는 환경에서 실시간으로 새로운 정보를 학습.
- 개인화 : 개별 사용자나 조직의 특성에 맞춰 더욱 세밀하게 적응하는 기술로 발전.
RAFT는 LLM의 도메인 적응 분야에 새로운 바람을 일으키고 있습니다. 이를 통해 더욱 정확하고 맥락에 맞는 AI 응답 생성이 가능해질 것이고, 다양한 산업 분야에서 AI의 활용도가 더욱 높아질 것으로 기대됩니다.



