이번 블로그에서는 Semantic Kernel이 무엇인지, LangChain과는 어떻게 다른지 간단하게 비교해보고 Text-to-SQL 시나리오를 예시로 어떻게 구현하는지 알아보도록 하겠습니다.
Semantic Kenrel이란?
Semantic Kernel은 AI 에이전트를 쉽게 구축하고 최신 AI 모델을 C#, Python 또는 Java 코드베이스에 통합할 수 있는 마이크로소프트에서 개발한 오픈 소스 프레임워크입니다. 이를 통해 개발자는 자연어 처리, 추론, 계획 수립 등 다양한 AI 기능을 애플리케이션에 손쉽게 통합할 수 있습니다.
Introduction to Semantic Kernel
Learn about Semantic Kernellearn.microsoft.com
Semantic Kernel vs LangChain
모두 AI 애플리케이션 개발을 용이하게 하도록 설계되었지만, 몇 가지 주요 차이점이 있습니다.
출시 시기 및 배경LangChain은 2022년 10월에 출시되었으며, 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 지원하는 파워풀한 프레임워크로, 다양한 AI 모델과 시스템을 연결하고 확장할 수 있는 기능을 제공합니다.
Semantic Kernel은 2023년 3월에 공개되었으며, Microsoft에서 개발한 오픈소스 프레임워크로, .NET 환경에서 AI 모델의 통합과 오케스트레이션을 용이하게 합니다.
핵심 구성 요소LangChain은 다음과 같은 핵심 구성 요소를 통해 AI 워크플로우를 구성합니다.
- Chains: 여러 단계를 거쳐 작업을 수행하는 프로세스
- Agents: 대화형, 계획 및 실행, ReAct, 사고 트리(ToT) 접근 방식을 지원하는 AI 오케스트레이션 도구
- Tools: 외부 도구와의 통합을 위한 인터페이스
- Memory: 상태를 유지하고 이전 정보를 활용하는 기능
Semantic Kernel은 다음과 같은 구성 요소를 통해 AI 기능을 통합합니다:
- Kernel: AI 기능을 호스팅하는 중심 컴포넌트
- Planner: 계획 및 실행(SequentialPlanner)과 ReAct(StepwisePlanner) 접근 방식을 지원하는 AI 오케스트레이션 도구
- Plugins: 다양한 플러그인을 활용하여 기능을 확장하는 모듈
- Memory: 상태를 유지하고 이전 정보를 활용하는 기능
LangChain은 다음과 같은 RAG 지원 및 통합 기능을 제공합니다.
- 문서 로더: 100개 이상의 문서 로더를 지원하여 다양한 파일 유형과 웹 소스에서 데이터를 가져올 수 있습니다.
- 문서 변환기: 여러 분할 방법을 제공하여 문서를 다양한 방식으로 처리할 수 있습니다.
- 텍스트 임베딩 모델: 25개 이상의 임베딩 제공자와 통합되어 있어 다양한 임베딩 옵션을 제공합니다.
- 벡터 저장소: 50개 이상의 벡터 저장소와 통합되어 있어 데이터 저장 및 검색에 유연성을 제공합니다.
- 검색기: 의미론적 검색, 컨텍스트 압축, 앙상블 검색기 등 다양한 검색 방법을 제공합니다.
Semantic Kernel은 다음과 같은 RAG 지원 및 통합 기능을 제공합니다.
- 문서 로더: 주로 Word 문서에 대한 지원에 집중되어 있습니다.
- 문서 변환기: 이 기능이 제한적입니다.
- 텍스트 임베딩 모델: OpenAI, Azure OpenAI, Hugging Face와의 통합을 지원합니다.
- 벡터 저장소: 약 10개의 벡터 저장소를 지원합니다.
- 검색기: 주로 간단한 의미론적 검색을 지원합니다.
LangChain은 다양한 AI 모델과의 통합을 통해 복잡한 작업을 수행할 수 있게 해주는 프레임워크로, 주로 자연어 처리 작업에서 여러 모델의 조합을 통해 더 정교한 결과를 얻기 위해 사용됩니다.
Semantic Kernel은 특히 개발자가 기존 코드베이스에 AI 기능을 직접 통합하고 확장할 수 있도록 설계되었으며, 모듈식 구조를 통해 다양한 플러그인을 활용할 수 있습니다.
언어 및 플랫폼 지원LangChain은 Python과 JavaScript를 기반으로 한 프레임워크로, 다양한 사전 구축된 도구와 플러그인, 그리고 활발한 커뮤니티 지원을 제공합니다.
Semantic Kernel은 .NET 환경과의 통합에 중점을 두며, 보다 가벼운 구조를 가지고 있습니다.
어떤 프레임워크를 선택해야 할까?프로젝트의 요구 사항과 기존 기술 스택에 따라 적합한 프레임워크를 선택하는 것이 중요합니다.
- .NET 환경에서의 통합: 기존 .NET 코드베이스와의 통합을 고려한다면 Semantic Kernel이 적합할 수 있습니다.
- 다양한 도구와 커뮤니티 지원: 다양한 사전 구축된 도구와 커뮤니티 지원을 원한다면 LangChain이 더 나은 선택이 될 수 있습니다.
Semantic Kernel과 LangChain 모두 AI 개발을 위한 강력한 도구를 제공하지만, 현재 LangChain이 특히 데이터 연결과 검색 면에서 더 광범위한 기능과 통합을 제공합니다. 그러나 C#으로 작업하는 개발자나 Semantic Kernel이 제공하는 특정 기능이 필요한 경우에는 Semantic Kernel이 선호될 수 있습니다. 이 프레임워크들 중 선택은 프로젝트의 특정 요구 사항과 선호하는 프로그래밍 언어에 따라 달라진다고 볼 수 있습니다.
그럼 Semantic Kernel을 활용해 AI 애플리케이션은 어떻게 구현하는지 Text-to-SQL 시나리오를 통해 알아보도록 하겠습니다.
Semantic Kernel을 활용한 Text-to-SQL 구현
먼저, Text-to-SQL 기능을 구현할 때 다음과 같은 문제를 고려해야 합니다.
- 환각(Hallucination): LLM이 존재하지 않는 테이블이나 필드를 포함한 잘못된 SQL 쿼리를 생성할 수 있습니다. 이를 방지하기 위해 데이터베이스 스키마 정보를 LLM에 제공하여 실제 데이터베이스 구조에 기반한 쿼리를 생성하도록 해야 합니다.
- 컨텍스트 창 길이 제한: LLM은 처리할 수 있는 텍스트의 길이에 제한이 있습니다. 데이터베이스 스키마 정보가 방대할 경우, 이를 모두 LLM에 전달하기 어려울 수 있습니다. 따라서, 필요한 정보만을 선택적으로 제공하거나, 스키마 정보를 요약하여 전달하는 등의 전략이 필요합니다.
- 쿼리 정확성: LLM이 생성한 SQL 쿼리가 문법적으로는 맞지만, 의도한 결과를 반환하지 않을 수 있습니다. 이러한 경우를 대비하여 쿼리 결과를 검증하고, 필요에 따라 쿼리를 수정하거나 재생성하는 로직을 구현해야 합니다.
이러한 부분을 고려하여 Semantic Kernel을 활용해 Text-to-SQL 기능을 구현하기 위해서는 다음과 같은 플러그인 구조를 설계할 수 있습니다.
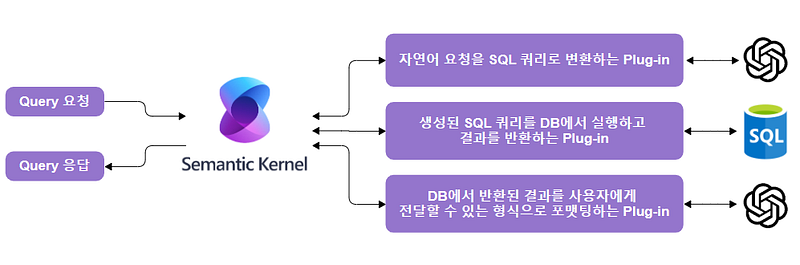
이제 Semantic Kernel과 Azure OpenAI를 활용하여 Text-to-SQL 기능을 구현하는 Python 코드를 살펴보겠습니다. 이 코드는 앞서 언급한 세 가지 플러그인 구조를 기반으로 합니다.
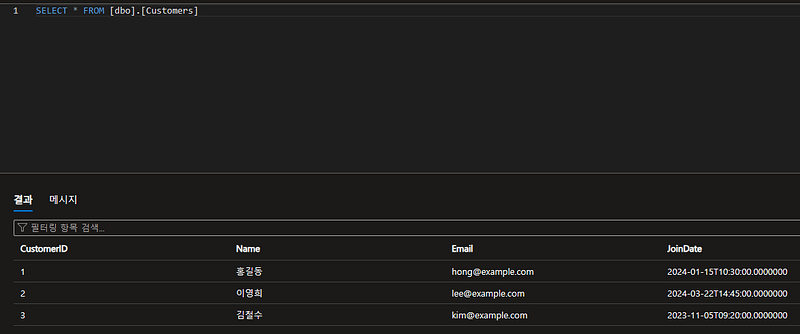
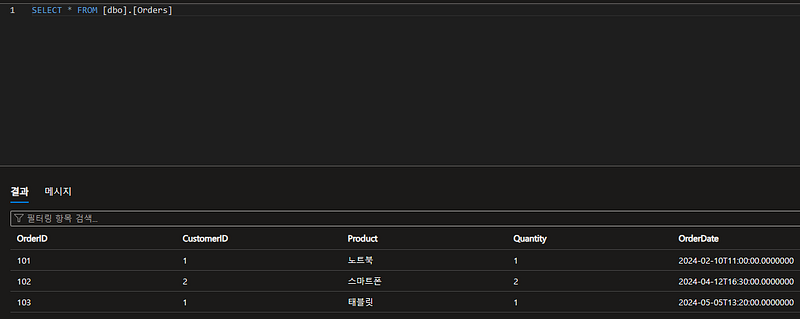
먼저, Azure SQL Database에는 아래와 같은 테이블과 데이터가 있습니다.
- 필요한 라이브러리 임포트
이 섹션에서는 프로젝트에 필요한 모든 라이브러리를 임포트합니다. Semantic Kernel, Azure OpenAI, 그리고 데이터베이스 연결을 위한 라이브러리들이 포함됩니다.
import os import json import pyodbc from semantic_kernel import Kernel from semantic_kernel.functions import kernel_function from semantic_kernel.functions.kernel_arguments import KernelArguments from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
2. 데이터베이스 연결 설정
Azure SQL 데이터베이스 연결을 위한 설정을 정의합니다.
SQL_CONFIG = {
"server": os.getenv("SQL_SERVER"),
"database": os.getenv("SQL_DATABASE"),
"username": os.getenv("SQL_USERNAME"),
"password": os.getenv("SQL_PASSWORD"),
"driver": os.getenv("SQL_DRIVER", "{ODBC Driver 18 for SQL Server}")
}
3. Semantic Kernel 초기화 및 Azure OpenAI 설정
Semantic Kernel을 초기화하고 Azure OpenAI 서비스를 추가합니다. 이는 자연어 처리 작업의 핵심이 됩니다.
# Semantic Kernel 초기화
kernel = Kernel()
# Azure OpenAI 서비스 추가
kernel.add_service(
AzureChatCompletion(
service_id="azure_open_ai",
deployment_name=os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME"),
endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY")
)
)
4. NLP → SQL 변환 플러그인
이 플러그인은 자연어 입력을 SQL 쿼리로 변환합니다. Semantic Kernel의 `kernel_function` 데코레이터를 사용하여 함수를 정의합니다.
# Semantic Kernel의 kernel_function 데코레이터 사용
class ConvertNlpToSqlPlugin:
@kernel_function(
name="nlp_to_sql",
description="자연어 설명을 바탕으로 SQL 쿼리 작성"
)
async def nlp_to_sql(self, user_input) -> str:
prompt = """
[역할]
당신은 SQL 전문가입니다. 주어진 요청 사항을 기반으로 정확한 SQL 쿼리를 생성하세요.
---
요청사항: {{$request}}
---
[테이블 스키마]
다음 테이블을 기반으로 SQL 쿼리를 작성해야 합니다.
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name NVARCHAR(50) NOT NULL,
Email NVARCHAR(50) UNIQUE,
JoinDate DATETIME DEFAULT GETDATE()
);
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT FOREIGN KEY REFERENCES Customers(CustomerID),
Product NVARCHAR(50)
CONSTRAINT CK_Orders_Product
CHECK (Product IN ('노트북', '스마트폰', '태블릿')),
Quantity INT CHECK (Quantity > 0),
OrderDate DATETIME
);
- Customers 테이블은 고객 정보를 포함하며, CustomerID는 기본 키입니다.
- Orders 테이블은 주문 정보를 저장하며, CustomerID는 Customers 테이블의 외래 키입니다.
- Product는 '노트북', '스마트폰', '태블릿' 중 하나여야 합니다.
- Quantity는 0보다 커야 합니다.
- JoinDate와 OrderDate는 날짜 필드입니다.
[규칙]
- 출력은 항상 유효한 SQL 쿼리여야 합니다.
- 테이블 스키마를 준수하며, 잘못된 컬럼명을 사용하지 않습니다.
- 불필요한 복잡성을 피하고 최적화된 SQL을 생성합니다.
- 필요한 경우 JOIN, WHERE, GROUP BY, ORDER BY를 적절히 사용합니다.
- 출력 형식은 SQL 코드 블록(sql ... )을 제외해야 합니다.
- 날짜 기반 쿼리의 경우 'YYYY-MM-DD' 형식으로 비교합니다.
SQL 쿼리:
"""
# Semantic Kernel의 KernelArguments 사용
arguments = KernelArguments(request=user_input)
# Semantic Kernel의 invoke_prompt 메서드 사용
raw_sql = await kernel.invoke_prompt(prompt=prompt, arguments=arguments)
generated_sql = str(raw_sql).strip()
print(f"[생성된 Query]\n{generated_sql}")
return generated_sql
5. SQL 실행 플러그인
이 플러그인은 생성된 SQL 쿼리를 실행하고 결과를 반환합니다. 역시 `kernel_function` 데코레이터를 사용합니다.
# Semantic Kernel의 kernel_function 데코레이터 사용
class QueryDbPlugin:
@kernel_function(
name="execute_query",
description="데이터베이스에서 SQL 쿼리 실행"
)
async def execute_query(self, query: str) -> list:
cleaned_query = query.strip()
conn_str = f"DRIVER={SQL_CONFIG['driver']};SERVER={SQL_CONFIG['server']};DATABASE={SQL_CONFIG['database']};UID={SQL_CONFIG['username']};PWD={SQL_CONFIG['password']};Encrypt=yes;TrustServerCertificate=no;"
try:
with pyodbc.connect(conn_str) as conn:
cursor = conn.cursor()
cursor.execute(query)
return [dict(zip([col[0] for col in cursor.description], row))
for row in cursor.fetchall()]
except pyodbc.Error as e:
return print("DATABASE_ERROR", f"데이터베이스 오류: {str(e)}")
6. 응답 포맷팅 플러그인
이 플러그인은 데이터베이스 쿼리 결과를 사용자 친화적인 형식으로 변환합니다.
# Semantic Kernel의 kernel_function 데코레이터 사용
class FormatResponsePlugin:
@kernel_function(
name="format_data",
description="쿼리 결과를 사용자 친화적 형식으로 변환"
)
async def format_data(self, db_result: str, user_input: str) -> str:
prompt = """
[사용자 요청]
{{$request}}
[쿼리 결과]
{{$result}}
[변환 규칙]
1. 기술적 용어 제거
2. 날짜는 'YYYY년 MM월 DD일' 형식
3. 숫자에 천 단위 구분기호 사용
4. 주요 통계 수치 강조
[예시]
결과: [{'Name':'홍길동', 'OrderDate': '2024-02-10 11:00:00'}]
응답: 홍길동 고객님은 2024년 02월 10일에 주문하셨습니다.
"""
# Semantic Kernel의 KernelArguments 사용
arguments = KernelArguments(request=user_input, result=db_result)
# Semantic Kernel의 invoke_prompt 메서드 사용
return await kernel.invoke_prompt(prompt=prompt, arguments=arguments)
7. 플러그인 등록
생성한 플러그인들을 Semantic Kernel에 등록합니다.
# Semantic Kernel의 add_plugin 메서드 사용 kernel.add_plugin(ConvertNlpToSqlPlugin(), "SqlGenerator") kernel.add_plugin(QueryDbPlugin(), "DbExecutor") kernel.add_plugin(FormatResponsePlugin(), "ResponseFormatter")
8. 워크플로우 실행 함수
전체 프로세스를 실행하는 함수를 정의합니다. 이 함수는 사용자 입력을 받아 SQL 생성, 쿼리 실행, 결과 포맷팅의 단계를 거칩니다.
# Semantic Kernel의 invoke 메서드와 get_function 메서드 사용
async def process_request(user_input):
arguments = KernelArguments(user_input=user_input)
# 1. SQL 생성 단계
sql_result = await kernel.invoke(kernel.get_function("SqlGenerator", "nlp_to_sql"), arguments)
sql_query = str(sql_result).strip()
arguments = KernelArguments(query=sql_query)
# 2. 쿼리 실행 단계
db_result = await kernel.invoke(kernel.get_function("DbExecutor", "execute_query"), arguments)
print(f"[Query 수행 결과]\n{db_result}")
db_result_str = str(db_result).strip()
arguments = KernelArguments(db_result=db_result_str, user_input=user_input)
# 3. 결과 포맷팅 단계
formatted_response = await kernel.invoke(kernel.get_function("ResponseFormatter", "format_data"), arguments)
return formatted_response
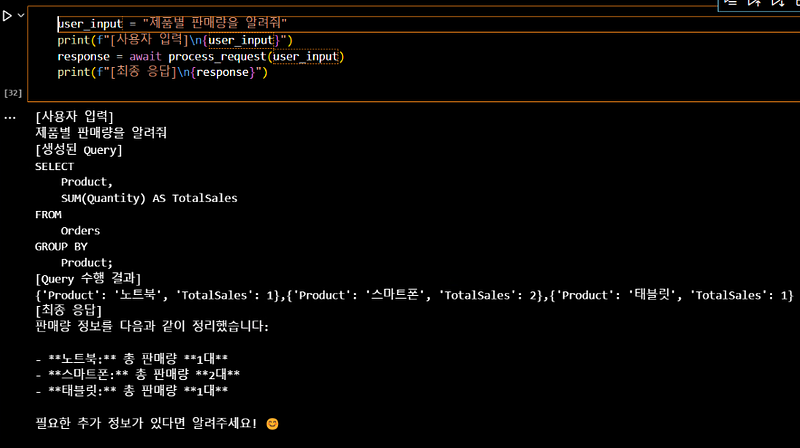
9. 실행 예시
마지막으로, 전체 시스템을 테스트하는 실행 예시를 제공합니다.
user_input = "제품별 판매량을 알려줘"
print(f"[사용자 입력]\n{user_input}")
response = await process_request(user_input)
print(f"[최종 응답]\n{response}")
최종적으로 아래와 같은 내용으로 출력되는 것을 볼 수 있습니다.