

데이터 플랫폼 구축을 하기 위해 AWS DMS(Database Migration Service)를 활용해 이기종 DB(MariaDB, MSSQL, Oracle)의 데이터를 S3(Parquet)로 적재하는 파이프라인을 구축했습니다.
DMS는 설정이 간편해 보이지만, 실무 환경에서 대용량 데이터를 다루다 보면 예상치 못한 복병을 자주 만나게 됩니다. 이번 포스팅에서는 제가 직접 부딪히며 깨달은 DMS 운영의 핵심 노하우와 주의사항을 정리해 공유합니다.
1. CloudWatch Logging
DMS Task의 진행 상황을 상세히 보고 싶은 마음에 모든 로그(Detailed Debug)를 켜는 것은 위험합니다.
-
문제점: 로그 데이터가 순식간에 쌓여 CloudWatch 스토리지 비용이 폭증하고 인스턴스 성능에 영향을 줍니다.
- Best Practice: 기본 로깅 레벨만 유지하세요. 에러 추적이 필요한 특정 상황에서만 잠시 레벨을 높이는 것이 운영의 묘미입니다.
2. CDC(Change Data Capture) 재시작 전략
CDC는 데이터의 연속성을 보장하는 핵심 기능이지만, 장애 발생 시 대처가 까다롭습니다.
-
Resume vs Start: 수동 중지 후에는
Resume이 잘 동작하지만, 예기치 못한 에러로 중단된 경우 다시 시작하는 과정에서 체크포인트 유실 위험이 있습니다. -
DBA 협조 필수: 특정 시점(LSN/SCN)부터 데이터를 다시 읽어야 할 경우, 소스 DB의 포지션을 직접 지정해야 합니다. 이때 DB 엔진에 대한 깊은 이해가 필요하므로 반드시 DBA와 협조하여 시작 지점을 협의하세요.
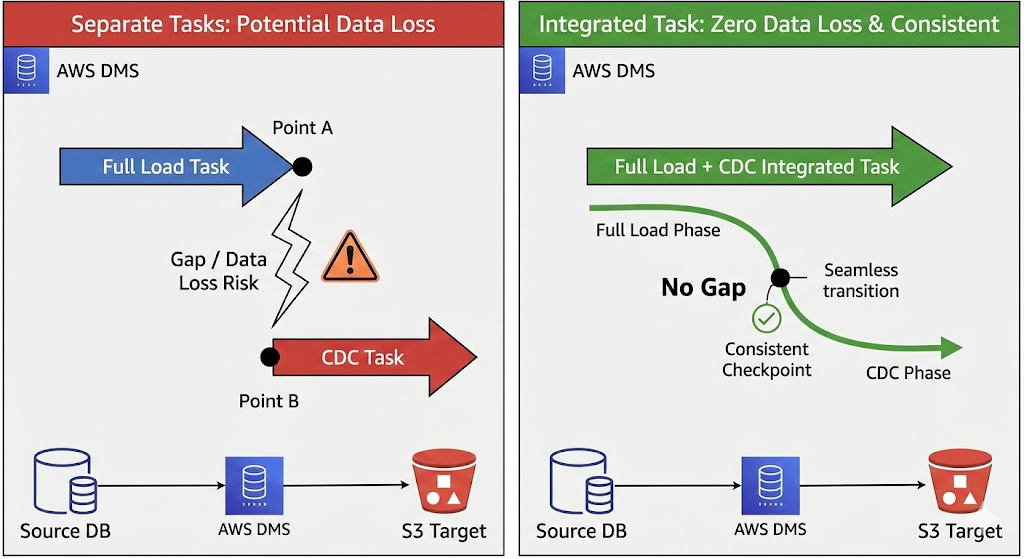
- 단, 포지션을 직접 지정하는 경우 Task 모드는 "CDC 단일" 일때만 가능합니다. - Task 구성 권장: AWS는 Full Load와 CDC가 결합된 단일 Task 사용을 권장합니다. 수동으로 각각 관리하면 두 단계 사이의 데이터 유실(Gap)을 완벽히 메우기가 매우 어렵기 때문입니다.
3. 트랜잭션 순서 보장 (Metadata 활용)
데이터 소스에 updated_at 컬럼이 없으면 S3에 저장된 데이터의 변경 순서를 알기 어렵습니다.
-
해결책: 테이블 매핑 설정 시
add-column기능을 사용하여 DMS 메타데이터 컬럼을 추가하세요.-
AR_H_STREAM_POSITION: 트랜잭션 위치 정보 -
AR_H_CHANGE_SEQ: 트랜잭션 내 변경 순서
-
- 이 두 컬럼이 있어야만 나중에 Athena나 Spark로 데이터를 조회할 때 최종 상태 값을 정확히 추려낼 수 있습니다.

4. DMS 데이터 마스킹, 어디까지 쓸모 있을까?
DMS는 기본적으로 3가지 마스킹을 지원하지만 제약 조건이 꽤 까다롭습니다.
-
숫자 마스킹/임의화: 주로 숫자형 컬럼에만 적용 가능하며 특수문자 변환 정도만 지원합니다.
-
해싱 마스크: String(64자 이상) 컬럼에서만 동작하므로 주민번호나 전화번호 같은 짧은 문자열에는 적용하기 어렵습니다.
- 결론: 복잡한 비즈니스 로직이 필요한 마스킹은 S3 적재 후 Glue나 Spark 같은 ETL 단계에서 처리하는 것이 훨씬 유연합니다.

5. 대용량 테이블(2~3천만 건 이상) 성능 튜닝
단순히 인스턴스 사양을 높이는(Scale-up) 것만이 답은 아닙니다. 비용 효율적인 설정을 고민해야 합니다.
- MaxFullLoadSubTasks: 기본값(8)은 운영 DB에 부하를 줄 수 있습니다. 안정성을 위해 2~3으로 낮추는 것을 권장합니다.

-
Swap 파일 방지: 변경분이 많은 테이블은 메모리 부족으로 디스크 Swap이 발생해 속도가 급격히 저하됩니다.
MemoryLimitTotal,MemoryKeepTime등의 파라미터를 상향 조정하여 메모리 내 처리 비중을 높여야 합니다.
6. Oracle 소스 사용 시 팁
- 엔드포인트 설정: 연결 속성을 하드코딩하는 방식보다는 AWS 콘솔의 전용 설정 UI를 활용하는 것이 인식이 더 정확합니다.

- 보관 주기(Retention): Oracle의 아카이브 로그 보관 주기가 짧으면 DMS가 로그를 읽기 전에 삭제되어 Task가 실패합니다. 소스 DB 측에 충분한 로그 보관 시간을 확보해달라고 요청하세요.

마치며
DMS는 이기종 간 데이터 이동을 도와주는 강력한 도구이지만, 소스 DB의 특성과 DMS의 내부 동작 방식을 제대로 이해하지 못하면 데이터 유실이나 성능 저하로 이어지기 쉽습니다.
이번에 구축한 파이프라인이 팀 내 데이터 플랫폼의 든든한 기초가 되길 바랍니다.



