

AI 기술의 발전은 정보 검색 및 생성 방식에 혁신을 가져왔습니다. 그중 RAG(Retriever-Augmented Generation) 패턴은 검색 기술과 대규모 언어 모델(LLM)을 결합하여 복잡한 질문에 답할 수 있는 강력한 도구로 자리 잡았습니다. 이번 글에서는 RAG의 기본 개념과 일반적인 사용 사례, 그리고 Azure를 활용해 Advanced RAG를 구현하며 기존 RAG 패턴의 한계를 어떻게 극복할 수 있는지 살펴보겠습니다.
[RAG(Retrieval-Augmented Generation)의 개념]
RAG는 대규모 언어 모델(LLM)의 성능을 향상시키는 기술로, 외부 지식 소스에서 관련 정보를 검색하여 LLM의 응답 생성에 활용합니다. 이 방식은 최신 정보 반영, 사실적 오류 감소, 그리고 도메인 특화된 지식 활용을 가능하게 합니다.RAG의 기본 워크플로우는 다음과 같습니다:
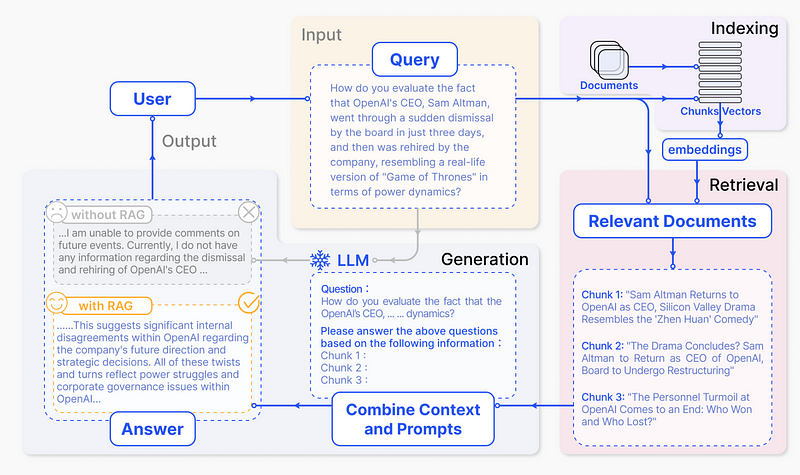
Better RAG 1: Advanced Basics(https://huggingface.co/blog/hrishioa/retrieval-augmented-generation-1-basics)
- 데이터 인덱싱: 문서를 청크로 나누고 임베딩하여 벡터 데이터베이스에 저장
- 쿼리 처리: 사용자 질문을 임베딩하여 관련 문서 검색
- 컨텍스트 생성: 검색된 문서를 바탕으로 LLM에 전달할 프롬프트 구성
- 응답 생성: LLM이 제공된 컨텍스트를 바탕으로 답변 생성
이러한 접근 방식은 LLM의 고유한 지식과 외부 데이터 소스의 최신 정보를 결합하여, 더욱 정확하고 맥락에 맞는 응답을 생성할 수 있게 합니다.
그렇다면 이러한 RAG 패턴이 어떻게 생겨났고, 어떻게 변화해왔는지에 대해서 알아보겠습니다.
[RAG의 진화와 패러다임 변화]
RAG의 발전 과정과 패러다임 변화를 학술적 관점에서 살펴보면 다음과 같습니다
- 전통적인 정보 검색 시스템
초기의 정보 검색 시스템은 주로 Boolean 모델과 벡터 공간 모델에 기반했습니다. 이 시스템들은 키워드 매칭에 의존하여 관련 문서를 찾았지만, 의미적 이해에는 한계가 있었습니다. - 신경망 기반 검색 모델
2000년대 후반부터 신경망을 활용한 정보 검색 모델이 등장했습니다. DSSM(Deep Structured Semantic Models)과 같은 모델은 쿼리와 문서를 동일한 의미 공간에 매핑하여 더 정확한 검색을 가능하게 했습니다.
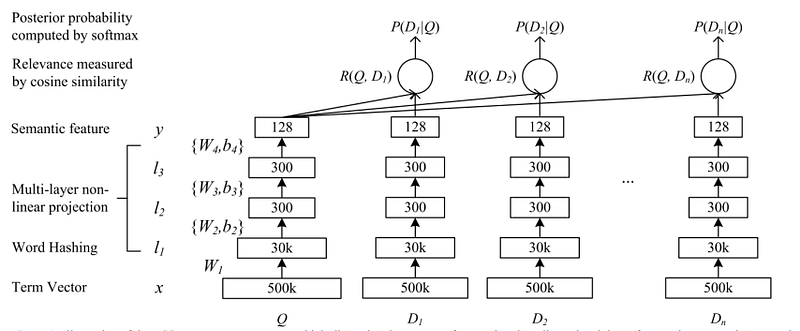
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data(https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf)
- 트랜스포머와 BERT의 등장
2018년 BERT의 등장으로 자연어 처리 분야에 큰 변화가 일어났습니다. BERT를 이용한 검색 모델은 문맥을 고려한 더 정교한 검색을 가능하게 했습니다. - RAG의 탄생
2020년 Facebook AI에서 발표한 “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” 논문은 RAG의 기본 개념을 소개했습니다. 이 모델은 파라메트릭 메모리(LLM)와 비파라메트릭 메모리(검색 시스템)를 결합하여 지식 집약적 태스크의 성능을 크게 향상시켰습니다.
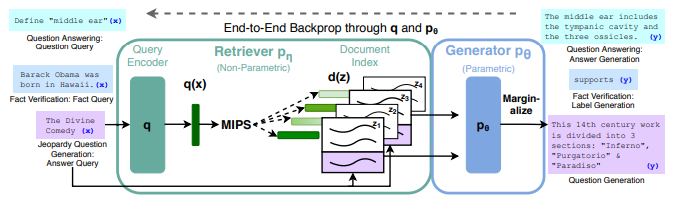
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(https://arxiv.org/pdf/2005.11401)
- 하이브리드 검색 기술
키워드 기반 검색과 의미론적 검색을 결합한 하이브리드 접근법이 등장했습니다. “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT” 논문은 이러한 하이브리드 접근법의 효과성을 입증했습니다. - 멀티 쿼리 확장
“Multi-Query Retrieval” 기법은 하나의 사용자 쿼리에서 여러 관련 쿼리를 생성하여 검색의 다양성과 정확성을 높였습니다. 이는 “Improving Passage Retrieval with Zero-Shot Question Generation” 논문에서 제안되었습니다. - 계층적 검색 및 재순위화
계층적 검색과 재순위화 기술은 검색 결과의 품질을 더욱 향상시켰습니다. “COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List” 논문은 이러한 접근법의 효과를 보여줍니다. - 멀티모달 RAG
텍스트뿐만 아니라 다양한 형태의 데이터를 처리하는 멀티모달 RAG 시스템이 개발되었습니다. “Multimodal Few-Shot Learning with Frozen Language Models” 논문은 이미지와 텍스트를 결합한 RAG 시스템의 가능성을 제시했습니다. - 자기 반영 및 추론 기반 RAG
최신 RAG 시스템은 자체 출력을 평가하고 필요한 경우 추가 정보를 검색하는 자기 반영 메커니즘을 포함합니다. “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection” 논문은 이러한 접근법의 효과성을 보여줍니다.
이러한 RAG의 진화는 정보 검색과 자연어 처리 분야에 큰 변화를 가져왔습니다. 단순한 정보 검색에서 시작하여 이제는 복잡한 질문에 대해 정확하고 맥락에 맞는 답변을 생성할 수 있는 수준에 이르렀습니다. 이는 AI 시스템의 지식 기반을 크게 확장시키고, 더욱 지능적이고 유용한 AI 애플리케이션의 개발을 가능하게 했습니다.
[일반적인 RAG 패턴의 한계]
RAG는 강력한 패턴이지만, 몇 가지 중요한 문제점을 가지고 있습니다.
- 검색 품질 저하
단순 키워드 검색은 질문의 맥락을 충분히 이해하지 못해 부정확한 정보를 반환할 수 있습니다. 이는 잘못된 답변 생성으로 이어질 수 있습니다. - 토큰 제한
언어 모델은 입력 길이에 제한이 있어 검색된 모든 정보를 사용할 수 없을 수 있습니다. - 실시간성 부족
데이터베이스가 최신 정보와 동기화되지 않으면 최신 데이터에 대한 답변이 불가능합니다. - 복잡한 쿼리 처리 부족
단순 키워드 기반 검색은 복잡한 논리나 상호 참조가 필요한 질문을 처리하는 데 한계가 있습니다. - 보안 및 프라이버시 문제
외부 데이터 소스와의 통합 과정에서 민감한 정보가 노출될 위험이 있습니다. - 응답 속도 저하
검색과 생성의 비효율적인 연결은 응답 속도를 떨어뜨리고 사용자 경험을 저하시킬 수 있습니다.
그렇다면 이러한 문제 및 제한 사항들을 해결하기 위해서 Advanced RAG를 구현하기 위해 Azure 환경에서는 어떻게 구성하는지 직접 살펴보겠습니다.
Azure에서 RAG를 구현하는 기본 단계는 다음과 같습니다:
- Azure OpenAI Service 설정
- Azure AI Search 구성
- 데이터 인덱싱 및 임베딩
- Azure Functions 또는 App Service를 사용한 API 개발
- 프론트엔드 애플리케이션 구축
[Advanced RAG 구현 (Hands-on Lab)]
이제 Azure를 사용하여 Advanced RAG를 구현하는 방법을 단계별로 살펴보겠습니다.
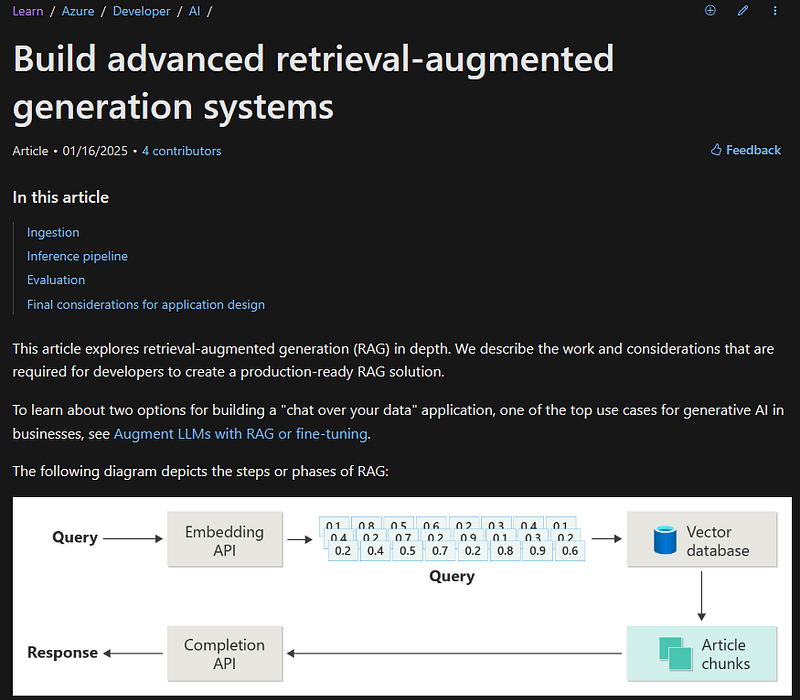
이론적인 내용은 하기의 링크를 참고할 수 있습니다.
Build Advanced Retrieval-Augmented Generation Systems
As a developer, learn about real-world considerations and patterns for retrieval-augmented generation (RAG)-based chat…learn.microsoft.com
1단계: 환경 설정
# Azure CLI 설치 (이미 설치되어 있다면 생략)
curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash
# Azure에 로그인
az login
# 리소스 그룹 생성
az group create --name myRAGResourceGroup --location eastus
2단계: Azure OpenAI Service 설정
# Azure OpenAI 리소스 생성
az cognitiveservices account create --name myOpenAI --resource-group myRAGResourceGroup --kind OpenAI --sku S0 --location eastus
# GPT-3.5 모델 배포
az cognitiveservices account deployment create --name myOpenAI --resource-group myRAGResourceGroup --deployment-name gpt35turbo --model-name gpt-35-turbo --model-version "0301" --model-format OpenAI
3단계: Azure AI Search 설정
# Azure AI Search 서비스 생성
az search service create --name mySearchService --resource-group myRAGResourceGroup --sku Basic
# 인덱스 생성 (JSON 파일을 사용하여 인덱스 스키마 정의)
az search index create --name myIndex --service-name mySearchService --resource-group myRAGResourceGroup --definition index-schema.json
4단계: 데이터 처리 및 인덱싱
Python 스크립트를 사용하여 데이터를 처리하고 Azure AI Search에 인덱싱합니다.
import os
import json
import nest_asyncio
import asyncio
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import SearchIndex, SimpleField, SearchFieldDataType, SearchableField
from azure.ai.textanalytics import TextAnalyticsClient
from openai import AzureOpenAI
# Azure 서비스 연결 설정
TEXT_ANALYTICS_ENDPOINT = os.getenv("TEXT_ANALYTICS_ENDPOINT")
TEXT_ANALYTICS_KEY = os.getenv("TEXT_ANALYTICS_KEY")
OPENAI_ENDPOINT = os.getenv("OPENAI_ENDPOINT")
OPENAI_KEY = os.getenv("OPENAI_KEY")
SEARCH_ENDPOINT = os.getenv("SEARCH_ENDPOINT")
SEARCH_KEY = os.getenv("SEARCH_KEY")
INDEX_NAME = os.getenv("INDEX_NAME")
# Azure 서비스 클라이언트 초기화
text_analytics_client = TextAnalyticsClient(endpoint=TEXT_ANALYTICS_ENDPOINT, credential=AzureKeyCredential(TEXT_ANALYTICS_KEY))
openai_client = AzureOpenAI(api_key=OPENAI_KEY, api_version="2023-05-15", azure_endpoint=OPENAI_ENDPOINT)
index_client = SearchIndexClient(endpoint=SEARCH_ENDPOINT, credential=AzureKeyCredential(SEARCH_KEY))
search_client = SearchClient(endpoint=SEARCH_ENDPOINT, index_name=INDEX_NAME, credential=AzureKeyCredential(SEARCH_KEY))
def create_search_index():
"""
Azure Cognitive Search 인덱스를 생성하는 함수입니다.
"""
fields = [
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SearchableField(name="content", type=SearchFieldDataType.String),
SearchableField(name="keywords", type=SearchFieldDataType.Collection(SearchFieldDataType.String)),
SearchableField(name="metadata", type=SearchFieldDataType.String)
]
index = SearchIndex(name=INDEX_NAME, fields=fields)
try:
index_client.create_index(index)
except Exception as e:
print(f"Index creation failed: {e}")
def chunk_document(content, max_chunk_size=500):
"""
긴 문서를 최대 크기 이하의 청크로 분할하는 함수입니다.
"""
words = content.split()
chunks = []
chunk = []
chunk_size = 0
for word in words:
if chunk_size + len(word) + 1 > max_chunk_size:
chunks.append(" ".join(chunk))
chunk = []
chunk_size = 0
chunk.append(word)
chunk_size += len(word) + 1
if chunk:
chunks.append(" ".join(chunk))
return chunks
def process_and_index_document(document):
"""
문서를 처리하고 Azure Cognitive Search에 인덱싱하는 함수입니다.
"""
key_phrase_result = text_analytics_client.extract_key_phrases([document["content"]])
keywords = key_phrase_result[0].key_phrases if key_phrase_result else []
keywords_str = json.dumps(keywords)
chunks = chunk_document(document["content"])
for i, chunk in enumerate(chunks):
search_client.upload_documents([{
"id": f"{document['id']}-{i}",
"content": chunk,
"keywords": keywords_str,
"metadata": json.dumps(document["metadata"])
}])
5단계: Advanced RAG 파이프라인 구현
async def run_query(query):
"""
주어진 쿼리에 대해 Azure Cognitive Search를 실행하는 비동기 함수입니다.
"""
results = search_client.search(search_text=query, top=2)
return list(results)
async def run_parallel_queries(queries):
"""
여러 쿼리를 병렬로 실행하는 비동기 함수입니다.
"""
tasks = [run_query(query) for query in queries]
return await asyncio.gather(*tasks)
def bm25_score(result, query):
"""
BM25 알고리즘을 사용하여 검색 결과의 점수를 계산하는 함수입니다.
"""
content = result.get("content", "")
return sum(content.lower().count(term.lower()) for term in query.split())
def rerank_results(results, query):
"""
검색 결과를 BM25 점수를 기준으로 재정렬하는 함수입니다.
"""
return sorted(results, key=lambda result: bm25_score(result, query), reverse=True)
def generate_context(results):
"""
상위 3개의 검색 결과를 기반으로 문맥을 생성하는 함수입니다.
"""
return "\n".join([result["content"] for result in results[:3]])
def generate_response(query, context):
"""
주어진 쿼리와 문맥을 기반으로 OpenAI 모델을 사용하여 응답을 생성하는 함수입니다.
"""
prompt = f"Context: {context}\n\nQuestion: {query}\n\nAnswer:"
response = openai_client.chat.completions.create(
model="gpt-35-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
def main():
"""
전체 프로세스를 실행하는 메인 함수입니다.
"""
create_search_index()
documents = [
{"id": "1", "content": "Azure Cognitive Services는 자연어 처리, 컴퓨터 비전, 음성 인식과 같은 강력한 AI 기능을 제공합니다.", "metadata": {"category": "AI", "topic": "Cognitive Services"}},
{"id": "2", "content": "Azure Search는 애플리케이션에 풍부한 검색 환경을 구축할 수 있도록 지원하는 완전 관리형 검색 서비스입니다.", "metadata": {"category": "Search", "topic": "Azure Search"}},
{"id": "3", "content": "Azure OpenAI Service는 비즈니스 워크플로우에 GPT-3와 같은 대형 언어 모델을 통합하여 요약 및 감정 분석과 같은 작업을 수행할 수 있게 합니다.", "metadata": {"category": "AI", "topic": "OpenAI Service"}},
{"id": "4", "content": "Advanced RAG(Retrieval-Augmented Generation)는 문서 검색과 생성형 AI를 결합하여 보다 정확하고 맥락적으로 관련성 있는 응답을 제공합니다.", "metadata": {"category": "AI", "topic": "Advanced RAG"}},
{"id": "5", "content": "Azure Blob Storage는 이미지, 비디오 및 문서를 포함한 비정형 데이터를 위한 확장 가능하고 비용 효율적인 스토리지 솔루션을 제공합니다.", "metadata": {"category": "Storage", "topic": "Blob Storage"}},
{"id": "6", "content": "Azure Kubernetes Service(AKS)는 클라우드에서 Kubernetes를 사용하여 컨테이너화된 애플리케이션을 배포 및 관리하는 작업을 간소화합니다.", "metadata": {"category": "DevOps", "topic": "Kubernetes"}},
{"id": "7", "content": "Azure Functions는 이벤트 중심 애플리케이션을 인프라 관리 없이 구축할 수 있는 서버리스 컴퓨팅 플랫폼을 제공합니다.", "metadata": {"category": "Serverless", "topic": "Azure Functions"}},
{"id": "8", "content": "Azure Synapse Analytics는 조직이 대규모 데이터 통합 및 빅데이터 분석을 수행할 수 있도록 지원합니다.", "metadata": {"category": "Analytics", "topic": "Synapse"}},
{"id": "9", "content": "Microsoft Power BI는 데이터를 시각화하고 대화형 대시보드를 생성하여 인사이트를 도출할 수 있도록 합니다.", "metadata": {"category": "Analytics", "topic": "Power BI"}},
{"id": "10", "content": "Azure DevOps는 개발팀에 버전 관리, CI/CD 및 프로젝트 관리 도구를 제공합니다.", "metadata": {"category": "DevOps", "topic": "DevOps Tools"}},
{"id": "11", "content": "Azure Security Center는 하이브리드 클라우드 워크로드 전반에 걸쳐 통합된 보안 관리와 고급 위협 방지 기능을 제공합니다.", "metadata": {"category": "Security", "topic": "Security Center"}},
{"id": "12", "content": "Azure Monitor는 애플리케이션과 인프라에 대한 완전한 관측성을 제공하며 사전적인 문제 해결을 가능하게 합니다.", "metadata": {"category": "Monitoring", "topic": "Azure Monitor"}},
{"id": "13", "content": "Azure Logic Apps는 워크플로우를 자동화하고 애플리케이션 및 서비스를 원활하게 통합할 수 있도록 합니다.", "metadata": {"category": "Automation", "topic": "Logic Apps"}},
{"id": "14", "content": "Azure Machine Learning은 데이터 과학자가 기계 학습 모델을 대규모로 구축, 학습, 배포할 수 있도록 합니다.", "metadata": {"category": "AI", "topic": "Machine Learning"}},
{"id": "15", "content": "Azure Virtual Machines는 Linux와 Windows를 지원하며 주문형 확장 가능한 컴퓨팅 자원을 제공합니다.", "metadata": {"category": "Compute", "topic": "Virtual Machines"}},
{"id": "16", "content": "Azure Networking 솔루션에는 애플리케이션 연결성과 보안을 향상시키는 Virtual Network, Load Balancer 및 Application Gateway가 포함됩니다.", "metadata": {"category": "Networking", "topic": "Networking Solutions"}},
{"id": "17", "content": "Microsoft Teams는 Azure Communication Services와 통합되어 원활한 커뮤니케이션 및 협업 기능을 제공합니다.", "metadata": {"category": "Collaboration", "topic": "Teams Integration"}},
{"id": "18", "content": "Azure Policy는 조직이 Azure 환경 전반에서 규정을 준수하고 리소스를 관리할 수 있도록 합니다.", "metadata": {"category": "Governance", "topic": "Azure Policy"}},
{"id": "19", "content": "Azure Backup은 데이터를 클라우드에서 간단하고 신뢰할 수 있는 방식으로 백업하고 복구할 수 있도록 지원합니다.", "metadata": {"category": "Backup", "topic": "Backup Solutions"}},
{"id": "20", "content": "Azure Databricks는 빅데이터 처리 도구와 통합되어 고급 분석 및 기계 학습 기능을 제공합니다.", "metadata": {"category": "Analytics", "topic": "Databricks"}}
]
for doc in documents:
process_and_index_document(doc)
user_query = "Advanced RAG의 장점은 무엇인가요?"
prompt = f"다음의 Input과 관련된 대체 질문 3개를 작성해주세요.:\n\nInput: {user_query}"
response = openai_client.chat.completions.create(
model="gpt-35-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
expanded_queries = [q.strip() for q in response.choices[0].message.content.split("\n") if q.strip()]
queries = [user_query] + expanded_queries[:3]
nest_asyncio.apply()
parallel_searchresults = asyncio.run(run_parallel_queries(queries))
reranked_results = [rerank_results(results, user_query) for results in parallel_searchresults]
context = generate_context(reranked_results[0]) # 첫 번째 쿼리 결과만 사용
response = generate_response(user_query, context)
print("User Query:", user_query)
print("Response:", response)
if __name__ == "__main__":
main()
실제로 테스트를 위해 위의 코드를 실행해보면 아래와 같은 결과를 출력합니다.

참고로, AI Search로 병렬 처리를 구현하는 부분의 경우 SearchClient로 구현 시 에러가 발생하여 asyncio를 사용했지만 AI Search의 파티션을 늘릴 경우 병렬 처리가 가능할 것으로 보입니다. (다만 비용은 많이 발생할 수 있습니다.)
결론적으로 Advanced RAG 구현은 쿼리 확장, 병렬 검색, 결과 재순위화 등의 고급 기술을 포함하고 있습니다. 이를 통해 더 정확하고 관련성 높은 응답을 생성할 수 있습니다.
Advanced RAG 기술은 LLM의 성능을 크게 향상시키며, Azure의 강력한 서비스들을 활용하여 효과적으로 구현할 수 있습니다. 이 가이드에서 소개한 방법들을 기반으로 자신의 use case에 맞게 RAG 시스템을 최적화하고 확장할 수 있을 것입니다. 지속적인 모니터링과 개선을 통해 더욱 정교한 AI 애플리케이션을 개발할 수 있습니다
[미래를 향한 도전과 기회]
RAG 기술은 계속해서 발전하고 있으며, 앞으로 더 많은 혁신이 예상됩니다. 실시간 학습 능력을 갖춘 적응형 RAG 시스템, 더욱 정교한 추론 능력을 가진 AI 등이 연구되고 있습니다. 이러한 발전은 AI가 더욱 지능적이고 유용한 도구로 진화할 수 있음을 시사합니다.Azure 플랫폼은 이러한 최신 기술을 빠르게 도입하고 있어, 기업들이 항상 최첨단 AI 솔루션을 활용할 수 있도록 지원합니다. RAG 기술의 발전과 Azure의 강력한 지원은 AI 기반 정보 검색 및 생성 분야에 무한한 가능성을 열어주고 있습니다.결론적으로, Advanced RAG는 단순한 기술 혁신을 넘어 우리가 정보와 상호작용하는 방식을 근본적으로 변화시키고 있습니다. Azure와 같은 강력한 클라우드 플랫폼의 지원을 받아, 이제 기업들은 이 혁신적인 기술을 실제 비즈니스 문제 해결에 적용할 수 있게 되었습니다. 앞으로 RAG 기술이 어떻게 발전하고, 우리의 일상과 업무를 어떻게 변화시킬지 지켜보는 것은 매우 흥미로울 것입니다.



