

이번 글에서는 Azure AI Search 서비스를 기반으로 RAG 패턴의 애플리케이션을 구현하는 경우 검색된 결과에 대한 문서 수준의 보안이 요구되는 경우 완벽한 문서 수준의 보안 보다는 좀 완화할 수 있는 해결 방안에 대해 다루고자 합니다.
Azure AI Search서비스는 기본적으로는 문서 수준의 세분화된 권한 관리를 제공하지 않으며, 사용자별 권한에 따라 동일한 인덱스 내에서 검색 결과를 조정할 수 없습니다.
이러한 제한을 극복하기 위한 효과적인 방법 중 하나는 각 문서에 그룹 또는 사용자 ID를 나타내는 문자열 필드를 추가하고, 이를 기반으로 검색 시 필터를 적용하여 사용자 권한에 맞는 결과만을 노출하는 것입니다. 이러한 보안 필터링 패턴은 Azure AI Search에서 문서 수준 보안을 구현하는 데 유용하며, 특히 search.in 함수를 활용하면 복잡한 필터 표현식을 간소화하고 쿼리 성능을 향상시킬 수 있습니다.
[보안 필터링 패턴 구현 단계]
- 콘텐츠 준비: 먼저, 각 문서에 해당 문서에 액세스할 수 있는 사용자나 그룹의 ID를 나타내는 필드를 추가합니다. 이 필드는 쉼표로 구분된 문자열로 여러 ID를 포함할 수 있습니다.
- 인덱스 생성 및 데이터 푸시: 이러한 보안 주체 식별자 필드를 포함하도록 인덱스 스키마를 정의하고, 준비된 문서를 Azure AI 검색 인덱스에 푸시합니다.
search.in함수 활용한 쿼리: 사용자가 검색을 수행할 때, 해당 사용자의 ID를 기반으로search.in함수를 사용하여 필터를 적용합니다. 예를 들어, 사용자의 ID가 'user1'인 경우,search.in(accessIds, 'user1')와 같은 필터를 사용하여 해당 사용자가 액세스할 수 있는 문서만 검색 결과에 포함시킵니다.
[search.in 함수의 장점]
- 간결한 표현: 복잡한 논리식을 단순화하여 가독성을 높입니다.
- 성능 향상: 대규모 데이터셋에서도 효율적인 필터링을 지원하여 쿼리 응답 시간을 단축시킵니다.
- 보안 주체 식별자 관리: 사용자나 그룹의 ID가 변경될 경우, 해당 정보를 신속하게 업데이트하여 필터링의 정확성을 유지해야 합니다.
- 데이터 동기화: 원본 데이터와 인덱스 간의 동기화를 주기적으로 수행하여 최신 권한 정보가 반영되도록 합니다.
[구현 방법]
인덱스로 활용할 샘플 데이터는 아래와 같습니다.
#allowed_groups 필드에 해당 컨텐츠에 접근이 가능한 사용자 그룹을 지정합니다.
documents = [
{
"id": "1",
"subject": "신입 직원 온보딩 프로세스",
"content": "신입 직원은 매주 월요일 오전 10시에 열리는 온보딩 세션에 참석해야 합니다. 이 세션에서는 회사 소개, 팀 미팅, 초기 서류 작업이 이루어집니다.",
"allowed_groups": ["ITGroup","HRGroup"]
},
{
"id": "2",
"subject": "행동 강령",
"content": "직원은 전문적인 태도를 유지하고, 동료를 존중하며, 회사의 핵심 가치를 준수해야 합니다.",
"allowed_groups": ["HRGroup"]
},
{
"id": "3",
"subject": "원격 근무 가이드라인",
"content": "원격 근무는 매니저의 승인을 받아야 하며, 역할이 허용되고 성과 기준을 충족해야 가능합니다.",
"allowed_groups": ["ITGroup"]
}
]
Filter를 적용할 필드는 collection으로 “allowed_users”:[“user2”, “user3”]과 같이 []안에 저장합니다.
그리고 아래와 같이 코드를 작성하여 인덱스를 생성하고, 해당 데이터를 인덱스에 넣는 인덱싱 과정을 거치고 필터링을 포함한 검색을 정의합니다.
import os
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
import json
import requests
# 환경변수에서 Azure AI Search 서비스 정보 가져오기
service_name = os.getenv("AZURE_SEARCH_SERVICE_NAME")
index_name = os.getenv("AZURE_SEARCH_INDEX_NAME")
admin_key = os.getenv("AZURE_SEARCH_ADMIN_KEY")
openai_api_key = os.getenv("AZURE_OPENAI_API_KEY")
openai_endpoint = os.environ["AZURE_OPENAI_ENDPOINT"]
# Payload Header 설정
headers = {
'Content-Type': 'application/json',
'api-key': admin_key
}
params = {'api-version': "2024-07-01"}
# Index Payload 설정
index_payload = {
"name": index_name,
"vectorSearch": {
"algorithms": [
{
"name": "myalgo",
"kind": "hnsw"
}
],
"vectorizers": [
{
"name": "openai",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": openai_endpoint,
"apiKey": openai_api_key,
"deploymentId": "text-embedding-ada-002",
"modelName": "text-embedding-ada-002"
}
}
],
"profiles": [
{
"name": "myprofile",
"algorithm": "myalgo",
"vectorizer": "openai"
}
]
},
"semantic": {
"configurations": [
{
"name": "my-semantic-config",
"prioritizedFields": {
"titleField": {
"fieldName": "subject"
},
"prioritizedContentFields": [
{
"fieldName": "content"
}
],
"prioritizedKeywordsFields": []
}
}
]
},
"fields": [
{
"name": "id",
"type": "Edm.String",
"key": "true",
"analyzer": "keyword",
"searchable": "true",
"retrievable": "true",
"sortable": "false",
"filterable": "false",
"facetable": "false"
},
{
"name": "subject",
"type": "Edm.String",
"searchable": "true",
"retrievable": "true",
"facetable": "false",
"filterable": "true",
"sortable": "false"
},
{
"name": "content",
"type": "Edm.String",
"searchable": "true",
"retrievable": "true",
"sortable": "false",
"filterable": "false",
"facetable": "false"
},
{
"name": "allowed_groups",
"type": "Collection(Edm.String)",
"filterable": "true",
"retrievable": "false"
},
{
"name": "chunkVector",
"type": "Collection(Edm.Single)",
"dimensions": 1536,
"vectorSearchProfile": "myprofile",
"searchable": "true",
"retrievable": "true",
"filterable": "false",
"sortable": "false",
"facetable": "false"
}
]
}
# 인덱스 생성
r = requests.put(
f"https://{service_name}.search.windows.net/indexes/{index_name}",
data=json.dumps(index_payload),
headers=headers,
params=params
)
print(r.status_code)
print(r.ok)
print(r.text)
# 문서 데이터
documents = [
{
"id": "1",
"subject": "신입 직원 온보딩 프로세스",
"content": "신입 직원은 매주 월요일 오전 10시에 열리는 온보딩 세션에 참석해야 합니다. 이 세션에서는 회사 소개, 팀 미팅, 초기 서류 작업이 이루어집니다.",
"allowed_groups": ["ITGroup","HRGroup"]
},
{
"id": "2",
"subject": "행동 강령",
"content": "직원은 전문적인 태도를 유지하고, 동료를 존중하며, 회사의 핵심 가치를 준수해야 합니다.",
"allowed_groups": ["HRGroup"]
},
{
"id": "3",
"subject": "원격 근무 가이드라인",
"content": "원격 근무는 매니저의 승인을 받아야 하며, 역할이 허용되고 성과 기준을 충족해야 가능합니다.",
"allowed_groups": ["ITGroup"]
}
]
# 문서 인덱싱
index_documents_url = f"https://{service_name}.search.windows.net/indexes/{index_name}/docs/index"
index_documents_payload = {"value": documents}
r = requests.post(
index_documents_url,
data=json.dumps(index_documents_payload),
headers=headers,
params=params
)
print(r.status_code)
print(r.ok)
print(r.text)
# 사용자별 문서 검색 함수 정의
def search_documents_for_user(user_id):
search_client = SearchClient(
endpoint=f"https://{service_name}.search.windows.net",
index_name=index_name,
credential=AzureKeyCredential(admin_key)
)
# 사용자별 필터링 적용
filter_query = f"allowed_groups/any(u:search.in(u, '{user_id}'))"
results = search_client.search(search_text="*", filter=filter_query)
for result in results:
print(f"Document ID: {result['id']}, Content: {result['content']}")
그리고 예시에 나온 HRGroup, ITGroup에 대해 접근이 가능한 문서를 해당 인덱스에서 검색해 봅니다.
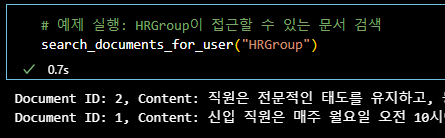
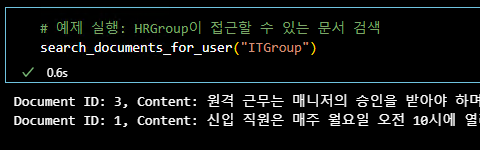
결과를 확인해보면 allowed_groups라고 명시된 필드값에 따라서 검색이 가능한 문서가 다른 것을 볼 수 있습니다.
물론 테스트한 코드와 같이 구성한다면 기능 구현은 가능하지만 실제로 실무에서 사용한다고 하면 좀 더 보안을 고려해야 합니다.
MS에서는 보안을 위해 아래와 같이 EntraID를 기반으로 인증을 구현하는 방식을 가이드하고 있습니다.
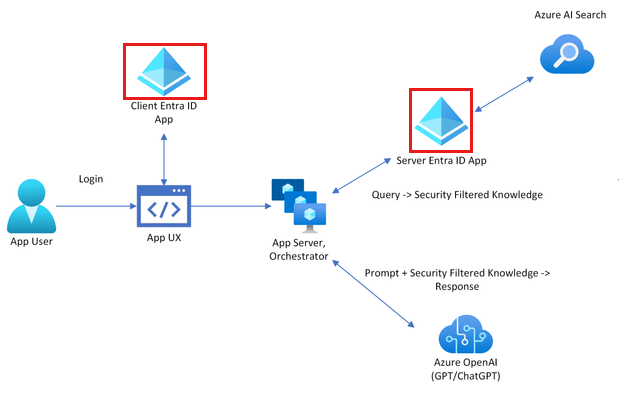
그리고 Entra ID를 기반으로 Index에 접근이 가능한 User ID를 정의하여 필터링을 구성해 해당 UserID에서 접근 가능한 문서만 볼 수 있도록 구현할 수 있습니다.
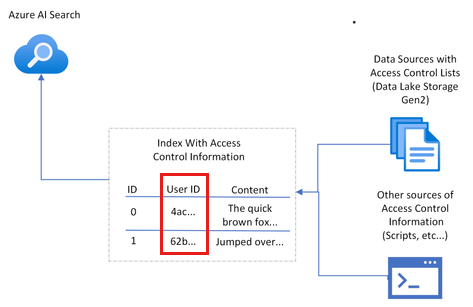
[결론]
Azure AI 검색에서 기본적으로 문서 수준의 보안을 직접 제공하지 않지만, 보안 필터링 패턴과 search.in 함수를 활용하여 사용자별로 검색 결과를 조정할 수 있습니다. 이를 통해 사용자 권한에 따른 맞춤형 검색 결과를 제공함으로써 보안 요구 사항을 충족시키고, 사용자 경험을 향상시킬 수 있습니다.
Azure AI Search의 결과를 한정하기 위한 보안 필터:
https://learn.microsoft.com/ko-kr/azure/search/search-security-trimming-for-azure-search?wt.mc_id=AZ-MVP-5002068
Python용 채팅 문서 보안 시작:
https://learn.microsoft.com/ko-kr/azure/developer/python/get-started-app-chat-document-security-trim?wt.mc_id=AZ-MVP-5002068&tabs=github-codespaces



